卡农社区羊毛专区监控 py 脚本变量
变量消息 TK
PUSHPLUS_TOKENS
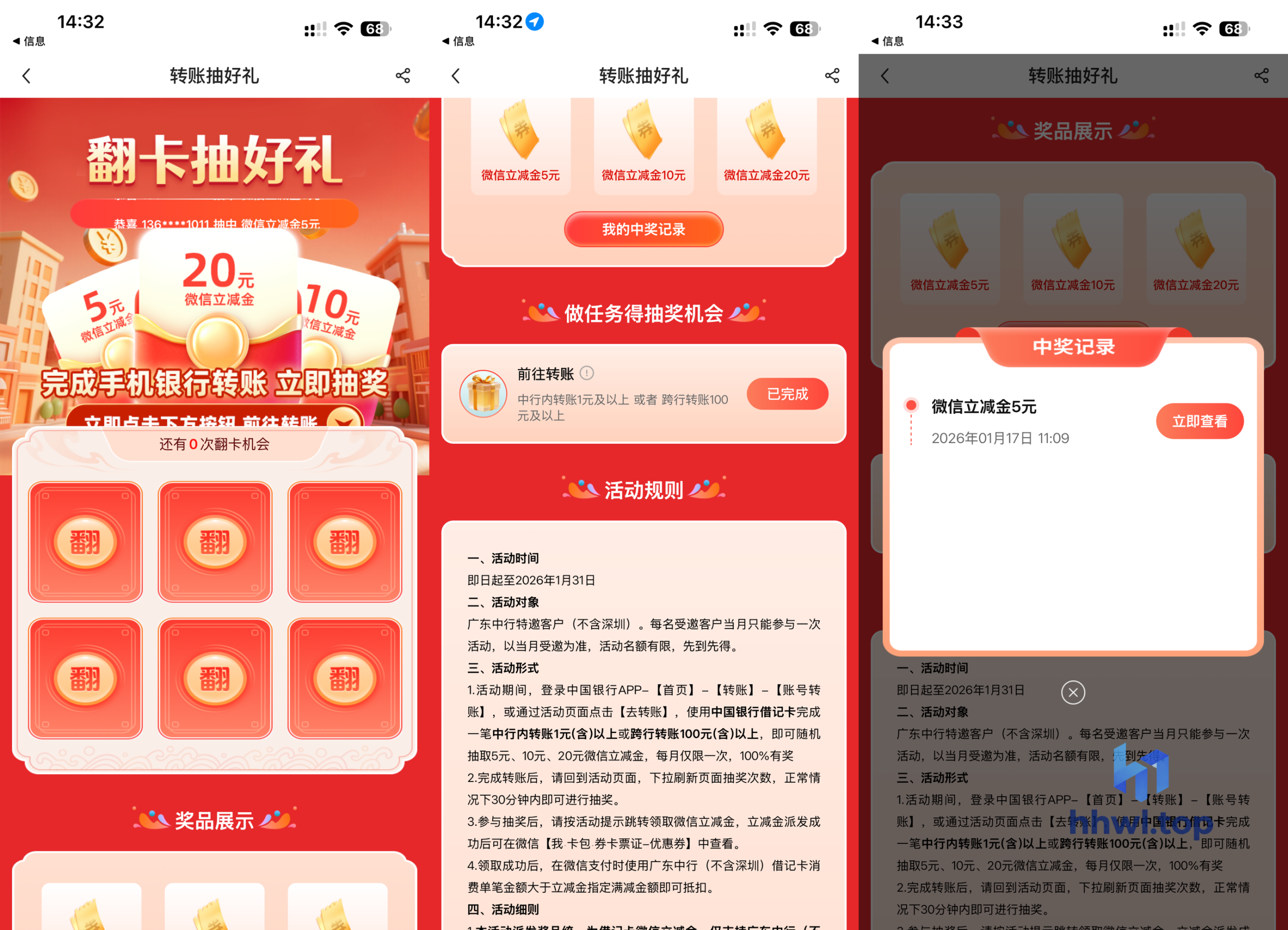
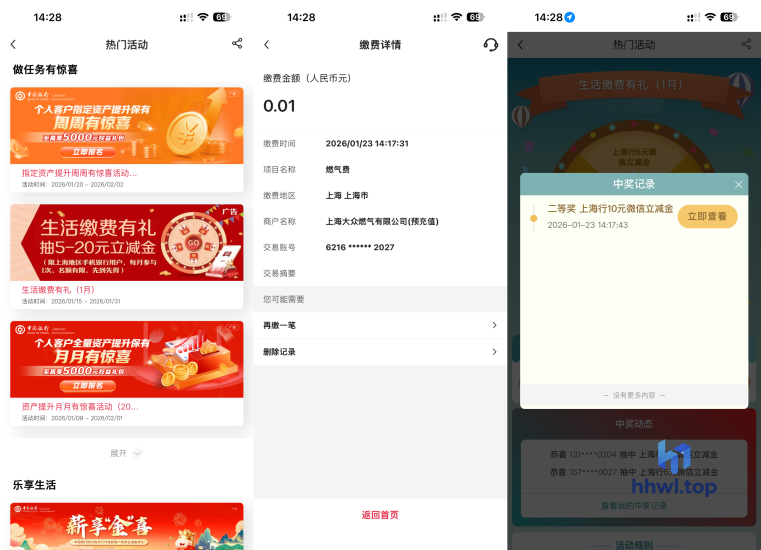
推送微信最新帖子
import requests
from bs4 import BeautifulSoup
import time
import os
import json
import re
import sys # 新增:用于退出脚本
from urllib.parse import quote
# 从环境变量读取多个Token,支持换行(\n)、井号(#)、逗号(,)分隔
def load_pushplus_tokens():
token_env = os.getenv("PUSHPLUS_TOKENS", "")
if not token_env:
print("【错误】未设置PUSHPLUS_TOKENS环境变量")
sys.exit(1) # 未配置环境变量,立即退出
# 按分隔符拆分Token,去重并过滤空值
separators = ["\n", "#", ","]
tokens = token_env
for sep in separators:
tokens = tokens.replace(sep, "|")
token_list = [t.strip() for t in tokens.split("|") if t.strip()]
# 去重
unique_tokens = list(dict.fromkeys(token_list))
if not unique_tokens:
print("【错误】PUSHPLUS_TOKENS环境变量中无有效Token")
sys.exit(1) # 无有效Token,立即退出
print(f"【配置】成功加载{len(unique_tokens)}个PushPlus Token")
return unique_tokens
# 配置项
MONITOR_URL = "https://www.51kanong.com/yh-282-1.htm"
CHECK_INTERVAL = 10
HISTORY_FILE = "post_history.json"
MAX_POSTS = 5 # 每次提取最新5条
TEST_POST_NUM = 2 # 启动后推送2条测试帖
POST_LINK_PATTERN = re.compile(r"(xyk|yh)-\d+-\d+\.htm")
INVALID_TITLES = ["全部", "首页", "板块", "交流", "推荐", "关于", "置顶"]
# 过滤规则:头像+广告+无关图关键词
INVALID_IMG_SUFFIX = [".gif", ".ico"]
IMG_BLACK_KEY = ["avatar", "head", "logo", "icon", "ad", "banner", "face", "smile", "user", "apple", "iphone", "logo"]
IMG_WHITE_KEY = ["羊毛", "红包", "任务", "优惠", "银行", "信用卡", "支付"]
IMG_WHITE_DOMAIN = ["img.51kanong.com", "attach.51kanong.com"]
PUSH_TITLE_PREFIX = "哗哗羊毛社区监控:" # 推送标题前缀配置
SNAPSHOT_DOMAIN = "http://py.hhwl.top/" # 快照网页域名
PUSH_TOKENS = load_pushplus_tokens() # 加载环境变量中的Token列表
TEST_COMPLETED = False # 测试帖推送完成标记
# 加载历史
def load_history():
if not os.path.exists(HISTORY_FILE):
with open(HISTORY_FILE, "w", encoding="utf-8") as f:
json.dump({"pushed_links": []}, f)
return {"pushed_links": []}
try:
with open(HISTORY_FILE, "r", encoding="utf-8") as f:
data = json.load(f)
return data if "pushed_links" in data else {"pushed_links": []}
except:
with open(HISTORY_FILE, "w", encoding="utf-8") as f:
json.dump({"pushed_links": []}, f)
return {"pushed_links": []}
# 保存历史
def save_history(pushed_links):
with open(HISTORY_FILE, "w", encoding="utf-8") as f:
json.dump({"pushed_links": pushed_links[-100:]}, f)
# 提取帖子链接
def extract_post_links():
try:
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 13; SM-G998B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Mobile Safari/537.36",
"Referer": "https://www.51kanong.com/",
"Cache-Control": "no-cache",
"Pragma": "no-cache"
}
response = requests.get(MONITOR_URL, headers=headers, timeout=15, allow_redirects=True)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
post_links = []
for a_tag in soup.find_all("a", href=POST_LINK_PATTERN):
post_href = a_tag.get("href")
post_title = a_tag.get_text(strip=True)
if not post_href or not post_title or post_title in INVALID_TITLES:
continue
full_link = f"https://www.51kanong.com/{post_href.lstrip('/')}"
post_links.append({"title": post_title, "url": full_link})
# 去重+取最新
unique_posts = []
seen_links = set()
for post in post_links:
if post["url"] not in seen_links:
seen_links.add(post["url"])
unique_posts.append(post)
return unique_posts[:MAX_POSTS]
except Exception as e:
print(f"【错误】提取链接失败:{str(e)[:50]}")
return []
# 校验图片是否和帖子内容相关
def is_img_related(img_src, post_text):
img_name = img_src.split("/")[-1].lower()
if any(kw in img_name for kw in IMG_WHITE_KEY) or any(kw in post_text.lower() for kw in IMG_WHITE_KEY):
return True
return False
# 提取帖子文字+有效图片
def extract_post_data(post_title, post_url):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 13; SM-G998B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Mobile Safari/537.36",
"Referer": "https://www.51kanong.com/"
}
response = requests.get(post_url, headers=headers, timeout=20, allow_redirects=True)
response.raise_for_status()
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, "html.parser")
# 提取文字内容
content_tags = [
soup.find("td", class_="t_f"),
soup.find("div", class_=lambda x: x and any(k in x for k in ["content", "post-content"]))
]
post_text = ""
for tag in content_tags:
if tag:
post_text = tag.get_text(strip=True, separator="\n")
post_text = "\n".join([line for line in post_text.split("\n") if line.strip()])
if post_text:
break
if not post_text:
post_text = f"【帖子核心】:{post_title}\n(该帖子无额外正文内容)"
# 提取有效图片
img_links = []
content_tag = soup.find("td", class_="t_f")
if content_tag:
img_tags = content_tag.find_all("img", src=True)
for img in img_tags:
img_src = img.get("src")
if not img_src:
continue
# 补全链接
if img_src.startswith("//"):
img_src = f"https:{img_src}"
elif not img_src.startswith("http"):
img_src = f"https://www.51kanong.com{img_src}"
# 过滤规则
if (any(domain in img_src for domain in IMG_WHITE_DOMAIN)
and not any(kw in img_src.lower() for kw in IMG_BLACK_KEY)
and is_img_related(img_src, post_text)):
img_links.append(img_src)
# 去重并取前2张
img_links = list(set(img_links))[:2]
return post_text, img_links
except Exception as e:
print(f"【错误】提取{post_url}数据失败:{str(e)[:50]}")
return f"【帖子核心】:{post_title}\n(提取异常:{str(e)[:30]})", []
# 推送文字+图片+超链接(支持多Token轮询)
def send_post_with_img(post_title, post_text, img_links, post_url, is_test=False):
# 测试帖添加标题标识
push_title = f"{PUSH_TITLE_PREFIX}[测试帖] {post_title}" if is_test else f"{PUSH_TITLE_PREFIX}{post_title}"
# 生成快照链接
snap_url = f"{SNAPSHOT_DOMAIN}?url={quote(post_url, safe='')}"
# 构造推送内容
push_content = post_text
if img_links:
push_content += "\n\n【帖子图片】:\n"
for img in img_links:
push_content += f'<img src="{img}" style="width:100%;max-width:500px;"/>\n'
push_content += f'\n\n【哗哗安卓快照网】:<a href="{snap_url}">点击查看快照</a>'
# 轮询所有Token,直到推送成功
for idx, token in enumerate(PUSH_TOKENS):
token_label = f"Token-{idx+1}"
try:
res = requests.post(
"http://www.pushplus.plus/send",
json={
"token": token,
"title": push_title,
"content": push_content,
"template": "html",
"channel": "wechat"
},
timeout=10
)
res_data = res.json()
if res_data.get("code") == 200:
print(f"【{'测试' if is_test else '成功'}】推送:{post_title[:20]}...({token_label})")
return True
else:
err_msg = res_data.get("msg", "未知错误")
# 服务端问题提示推送频繁
if "服务端验证错误" in err_msg or "用户账号使用受限" in err_msg:
print(f"【提示】推送{post_title[:20]}...:推送频繁({token_label}),尝试下一个Token")
else:
print(f"【失败】推送{post_title[:20]}...:{err_msg}({token_label}),尝试下一个Token")
except Exception as e:
err_info = str(e)[:30]
print(f"【错误】推送{post_title[:20]}...异常:{err_info}({token_label}),尝试下一个Token")
# 所有Token都失败
print(f"【最终失败】{'测试帖' if is_test else '推送'}:{post_title[:20]}... 所有Token均失败")
return False
# 推送测试帖
def push_test_posts():
print(f"\n【测试】开始提取{TEST_POST_NUM}条测试帖并推送...")
posts = extract_post_links()
if not posts:
print("【测试】提取不到测试帖,退出测试")
return
test_posts = posts[:TEST_POST_NUM]
for idx, post in enumerate(test_posts, 1):
print(f"\n【测试帖{idx}】标题:{post['title'][:30]}...")
post_text, img_links = extract_post_data(post["title"], post["url"])
send_post_with_img(post["title"], post_text, img_links, post["url"], is_test=True)
print(f"\n【测试】{len(test_posts)}条测试帖推送完成!\n" + "-"*50 + "\n")
# 主监控逻辑(添加免责声明和联系方式)
def monitor():
global TEST_COMPLETED
# 启动时显示免责声明和联系方式
print("="*60)
print("🚀 哗哗羊毛社区监控工具 - 启动成功")
print("⚠️ 免责声明:本工具仅作学习交流,请勿用于商业用途")
print("⚠️ 免责声明:数据来源为公开网络,侵删请联系作者")
print("✍️ 作者:哗哗 | QQ:64067887")
print("="*60)
print(f"【启动】监控开始 | 时间:{time.ctime()}")
print("="*60)
# 先推送测试帖
push_test_posts()
TEST_COMPLETED = True
pushed_links = load_history()["pushed_links"]
while True:
latest_posts = extract_post_links()
if not latest_posts:
time.sleep(CHECK_INTERVAL)
continue
new_posts = [p for p in latest_posts if p["url"] not in pushed_links]
if new_posts:
print(f"【通知】发现{len(new_posts)}条新帖")
for post in new_posts:
post_text, img_links = extract_post_data(post["title"], post["url"])
send_post_with_img(post["title"], post_text, img_links, post["url"])
pushed_links.append(post["url"])
save_history(pushed_links)
time.sleep(CHECK_INTERVAL)
if __name__ == "__main__":
monitor()
© 版权声明
本站内容均转载于互联网,并不代表本站立场!如若本站内容侵犯了原著者的合法权益,可联系我们进行处理!邮箱64067887@qq.com
拒绝任何人以任何形式在本站发表与中华人民共和国法律相抵触的言论!
THE END